
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- Instrumental Variable
- 인과추론
- 단순선형회귀
- residuals
- rct
- causal inference
- 예제
- 누락편의
- simple linear regression
- Python
- 선형대수
- 교란 변수
- LU분해
- 잔차의 성질
- confounder
- HTML
- OVB
- least square estimation
- Omitted Variable Bias
- 통계
- 크롤링
- 교란변수
- backdoor adjustment
- 머신러닝
- 네이버 뉴스
- 회귀불연속설계
- 인과 추론
- 최소제곱법
- 사영
- Sharp RD
- Today
- Total
Always awake,
PSM(Propensity Score Matching) 본문
본 포스팅은 인과추론을 위한 sub sampling 기법 중 하나인 성향 점수 매칭(propensity score matching)에 대해 정리한 글입니다 :)
개요
처치가 결과에 미치는 영향을 추론(인과 추론)하기 위해서는 처치를 받은 집단(실험군)과 받지 않은 집단(대조군)을 비교해야 합니다. 그리고 반드시 처치를 제외한 다른 조건은 두 집단 간 평균적으로 동일해야 합니다. 그래야 편향 없이 처치가 결과에 미치는 영향을 추론할 수 있습니다
하지만 현실에서는 처치 자체가 특정 요인에 영향을 받으며, 특정 요인이 결과에도 영향을 미치는 경우가 많습니다. 이를 교란 요인 (교란 변수) 이라고 합니다. 이러한 경우 교란 요인이 처치 여부에 미치는 영향을 제거해야 올바른 인과 효과를 추정할 수 있습니다. 즉, 처치 여부가 교란 요인에 의해 영향을 받지 않아야 하는 것이지요
교란 요인을 $C$, 처치 변수를 $T$(실험군을 1, 대조군을 0)라고 표현하면 교란 요인이 처치 여부에 미치는 영향은 $P(T|C)$로 표현할 수 있습니다.
여기서 어떤 성향($C$)에 따라 처치($T$)를 받을 확률을 성향 점수라고 합니다
$$\large{P(T|C)}$$


예를 들어 설명해보겠습니다. 우리는 프로모션을 진행하였고 프로모션이 매출에 미치는 영향을 추정하기 위해 프로모션을 구매한 집단, 구매하지 않은 집단의 매출을 비교하고자 합니다. 여기서 그림에서 보시는 것과 같이 "충성도"라는 교란 요인이 존재할 수 있습니다. 충성도가 높은 고객은 프로모션을 구매할 확률이 높은 것이지요. 따라서, 프로모션 구매 여부를 기준으로 두 집단을 나누면 그림과 같이 프로모션 구매 집단에는 충성도가 높은 고객의 비율이 높고, 미구매 집단에서는 충성도가 높은 고객의 비율이 낮습니다.
프로모션 구매가 매출에 미치는 인과 효과를 추정하기 위해서는 두 집단 간 프로모션 구매 여부를 제외한 나머지 요인의 분포는 평균적으로 동일해야하지만 교란 요인으로 인해 이를 위반하게 됩니다. 여기서 교란 요인이 처치에 영향을 미치는 것(충성도에 따른 프로모션 구매 여부)이 위에서 설명드린 성향 점수입니다
$$\large{P(프로모션 구매 여부 = 1 | 충성도)}$$
성향 점수 매칭
위에서 말씀드린 것처럼 교란 요인이 처치 여부에 영향을 미치는 상황에서는 두 집단(실험군, 대조군) 간 성향 점수의 분포가 다르게 나타납니다. 따라서 두 집단의 성향 점수 분포를 동일하게 만들어주는 작업이 필요합니다. 방법은 각 샘플에 대해서 성향 점수를 계산한 다음(샘플의 교란 요인의 값에 따라 처치를 받을 확률), 유사한 샘플끼리 매칭시켜 실험군, 대조군 그룹을 다시 구성하는 것입니다.
성향 점수 계산
정리하면 성향 점수 매칭은 두 집단 각각에서 유사한 샘플을 매칭시키는 sub sampling 방법이며, 매칭의 기준으로 성향 점수를 사용합니다. 두 집단에서 가장 유사한 샘플끼리 매칭시켜 처치를 제외한 다른 조건(교란 요인)을 통제하는 것이 목적입니다.
이 때 성향 점수를 추출하기 위해서는 로지스틱 회귀를 사용합니다. 로지스틱 회귀는 결과 변수가 binary class(1, 0)인 상황에서 특정 변수가 주어졌을 때 결과 변수가 1일 확률을 추정할 수 있기 때문입니다.
$$ \large{P(결과변수 = 1 | 특정 변수)} $$
예시
성향 점수 매칭을 이용한 인과 추론을 예시 데이터를 통해 확인해보겠습니다
데이터 생성
우선 처치 여부가 교란 요인에 영향을 받는 예시 데이터를 생성합니다. 대조군이 실험군에 비해 샘플 수가 많습니다.
우리가 추정해야 하는 인과 효과(처치 변수$T$가 결과 변수 $Y$에 미치는 영향)은 $3$ 입니다
참고로, uniform distribution의 값의 범위를 [0,2]로 한 이유는 대조군의 샘플 수가 실험군 보다 많게 설정하기 위해서입니다. (실제 현실에서는 대부분 실험군의 샘플 수가 대조군에 비해 적습니다)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels as sm
import statsmodels.formula.api as smf
np.random.seed(777)
N = 1000 # 샘플 수
# 인과 효과, 교란 요인이 결과 변수에 미치는 영향
treat_effect, confounding_effect = 3, 10
# 교란 요인
C = np.random.normal(0, 2, size = N)
C_minmax = (C - C.min()) / (C.max() - C.min()) # 0 ~ 1 사이로 minmax scaling
# 처치 변수
# uniform distribution에서 샘플 수 만큼 샘플을 추출
# C_minmax 값이 클 수록(C의 값이 클수록) Y=1일(처치를 받을) 확률이 높도록 설정
# 즉, 교란 요인(C)의 값이 클수록 처치를 받을 확률을 높임(교란 요인이 처치 여부에 영향을 주는 상태)
T = np.where(np.random.uniform(-1,1, size = N) <= C_minmax, 1, 0)
# 결과 변수
Y = confounding_effect*C + treat_effect*T + np.random.normal(0, 1, size = N)
# 데이터프레임 생성
df = pd.DataFrame({'C' : C, 'T' : T, 'Y' : Y})
print(df.groupby('T').size()) # 실험군, 대조군 수 확인
분포 확인(매칭 없이)
실험군, 대조군 두 그룹 간에 처치 변수($T$)를 제외한 다른 요인의 분포는 평균적으로 동일해야 합니다.
아래 그림은 두 그룹 간 교란 요인에 대한 분포를 확인한 결과입니다. 보이는 것과 같이 교란 요인이 처치 여부에 영향을 미치기 때문에 두 그룹 간 교란 요인의 분포가 다르게 나타납니다 (교란요인의 CDF가 실험군이 대조군에 비해 낮게 깔려있기 때문에 실험군의 교란 요인 분포가 대조군에 비해 높은 값에 분포하고 있다는 것을 알 수 있습니다)
def plot_confounding_var_cdf_group(data, title):
data[data['T'] == 1]['C'].hist(cumulative = True, histtype = 'step', bins = 100, density = True, linewidth = 2)
data[data['T'] == 0]['C'].hist(cumulative = True, histtype = 'step', bins = 100, density = True, linewidth = 2)
plt.legend(['treated group (1)', 'control group (0)'], fontsize = 20)
plt.xlabel('C', fontsize = 20)
plt.xticks(fontsize = 20)
plt.ylabel('CDF', fontsize = 20)
plt.yticks(fontsize = 20)
plt.title(title, fontsize = 25)
plot_confounding_var_cdf_group(df, 'CDF of each group (not matched)')
plt.show()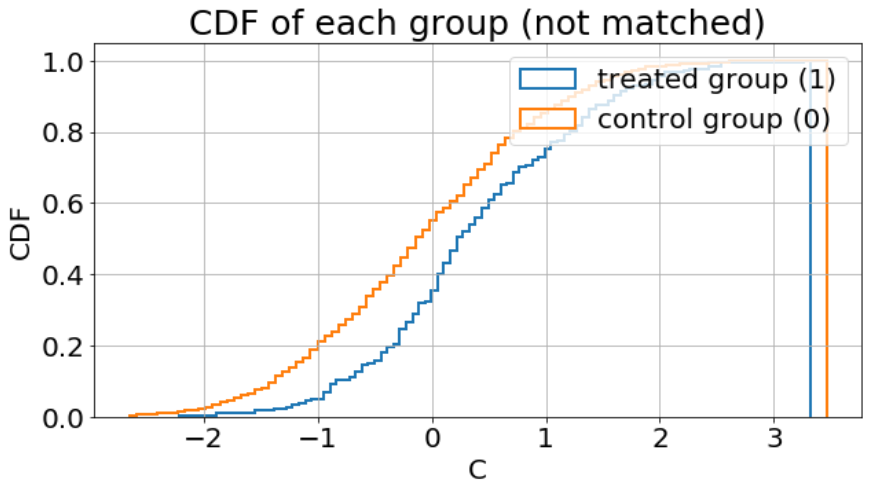
두 그룹 단순 비교(매칭 없이)
처치 변수가 결과 변수에 미치는 영향으로 7.6810이 나왔습니다. 두 집단 간 교란 요인의 분포가 다르기 때문에 우리가 설정한 인과 효과 값인 3이 나오지 않습니다. 즉, 교란 요인으로 인해 편향이 추가된 영향이 나옵니다
# 매칭 없이 Y ~ T 회귀식 fitting
smf.ols('Y ~ T', data = df).fit().summary().tables[1]
성향 점수 매칭
위에서 발생한 편향을 제거하기 위해서는 두 집단 간 교란 요인의 분포를 동일하게 맞춰주는 작업이 필요합니다. 이제 두 집단 간 교란 요인 분포를 동일하게 맞춰주기 위해 성향 점수 매칭을 사용하여 실험군, 대조군을 다시 구성해봅시다
from pymatch.Matcher import Matcher
treated_data = df[df['T'] == 1] # 실험군 데이터
control_data = df[df['T'] == 0] # 대조군 데이터
m = Matcher(treated_data, control_data, yvar="T", exclude=['Y']) # 설험군 데이터, 대조군 데이터, 처치 변수
m.fit_scores(balance=True, nmodels=100) # 로지스틱 회귀 학습
m.predict_scores() # 샘플별로 성향 점수 추출
m.match() # 추출된 성향 점수를 기준으로 실험군, 대조군 샘플 매칭
df_matched = m.matched_data # 매칭된 데이터
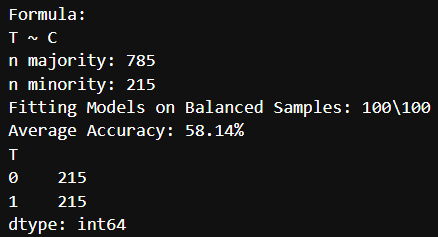
print(df_matched.groupby(['T']).size())성향 점수 매칭 결과입니다. 성향 점수($P(T|C)$)를 추정하는 모델을 학습하기 위해 회귀식을 T ~ C로 설정한 100개의 로지스틱 회귀 모델을 학습하였습니다
그 이후 모델을 이용하여 각 샘플의 성향 점수를 예측 후, 두 집단 간 성향 점수가 유사한 샘플끼리 매칭하였습니다. 그 결과 실험군과 대조군의 샘플 수가 각각 215개가 되었습니다. 즉, 대조군에서 실험군의 샘플과 성향 점수가 유사한 샘플만은 sub sampling하여 재구성한 것입니다 (그 이외의 샘플들은 버려지게 됩니다)
우리의 목적은 교란 요인이 처치 변수에 영향을 미치지 않도록 실험군, 대조군을 성향 점수 매칭을 통해 재구성하는 것이었습니다. 재구성된 데이터에서 실험군, 대조군의 교란 요인의 분포를 다시 비교해봅니다
그림에서 보시는 것과 같이 두 그룹 간 교란 요인 분포는 동일합니다. 이제 이 데이터로 두 그룹을 비교하게 되면 교란 요인에 의한 편향 없이 실험군, 대조군의 결과 변수를 비교할 수 있습니다(처치 변수가 결과 변수에 미치는 인과 효과)
plot_confounding_var_cdf_group(df_matched, 'CDF of each group (matched)')
인과 효과 추정(매칭 후)
성향 점수 매칭으로 재구성된 데이터를 이용하여 처치 변수가 결과 변수에 미치는 인과 효과를 선형 회귀를 이용하여 추정합니다
우리가 세팅한 인과 효과인 3과 유사한 값인 3.0187이 나왔습니다. 즉 편향이 없는 인과 효과를 추정할 수 있게 되었습니다.
# PSM을 이용하여 매칭된 데이터를 사용하여 Y ~ T fitting
smf.ols('Y ~ T', data = df_matched).fit().summary().tables[1]
참고) 다른 방법
참고로 매칭 기법을 활용하지 않고 회귀식에 교란 요인을 독립항으로 추가하여 통제하는 방법으로도 인과 효과를 추정할 수 있습니다.(교란 변수) 두 방법 중 어떤 것이 더 좋다고 말할 수는 없으나 성향 점수 매칭을 사용하면 두 집단 간의 비교 결과에 대한 이해가 더 직관적이라는 장점이 있다고 생각합니다
# 매칭 없이 Y ~ T + C fitting (교란 변수 C를 독립항으로 추가하여 통제하려는 목적)
smf.ols('Y ~ T + C', data = df).fit().summary().tables[1]
마치며
인과 효과 추정을 위해서 유사한 실험군, 대조군을 재구성하는 방법인 성향 점수 매칭에 대해 알아보았습니다
피드백은 언제나 환영합니다. 긴 글 읽어주셔서 감사합니다!
▼ 글이 도움이 되셨다면 아래 클릭 한번 부탁드립니다 :) ▼
'인과추론(Causal Inference)' 카테고리의 다른 글
| OPE(Offline Policy Evaluation) (0) | 2022.08.21 |
|---|---|
| [Causal Discovery] PC algorithm (4) | 2022.06.28 |
| MAB(Multi Armed Bandit) (2) | 2022.03.22 |
| 불연속회귀설계(RDD) 예제 (0) | 2021.10.24 |
| 이중차분법(DID) 예제 (0) | 2021.10.05 |



