
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- OVB
- backdoor adjustment
- LU분해
- 교란변수
- 통계
- rct
- residuals
- 머신러닝
- 회귀불연속설계
- 교란 변수
- Instrumental Variable
- simple linear regression
- Python
- 단순선형회귀
- 사영
- 인과 추론
- 크롤링
- 선형대수
- 예제
- 최소제곱법
- least square estimation
- confounder
- 누락편의
- 인과추론
- Omitted Variable Bias
- 네이버 뉴스
- causal inference
- HTML
- 잔차의 성질
- Sharp RD
- Today
- Total
Always awake,
[3탄] 쉽게 따라하는 네이버 뉴스 크롤링 - 본문 가져오기 본문
"본 포스팅은 네이버 뉴스의 title, url, 본문을 가져오는 크롤링을 설명하는 포스팅입니다
전 단계인 title, url 크롤링 방식을 확인하고 싶으신 분은 아래 링크(2탄)를 참고해주세요 :)"
히스토리
- (2021.02.14) 네이버 웹 페이지 구성이 바뀌어 내용, 코드 수정
- (2021.08.14) 네이버 웹 페이지 구성 변경, 언론사 필터링 검색 시 하나의 언론사만 선택 가능하여 내용, 코드 수정
[2탄] 쉽게 따라하는 네이버 뉴스 크롤링(python)
"본 포스팅은 네이버 웹 크롤링 실제 python 코드를 작성하는 2탄입니다. 전 단계인 수행계획을 확인하고 싶으신 분들은 아래링크(1탄)을 참고해주세요 :)" 쉽게 따라하는 네이버 뉴스 크롤링(python)
everyday-tech.tistory.com
지난 편에 이어 본 편에서는 저 나름대로 고민한 네이버 뉴스 본문을 크롤링하는 방법을 공유하고자 합니다.
먼저 본문 크롤링이 어려운 이유 먼저 살펴보겠습니다.
- 언론사마다 웹 페이지 구성이 다름
- 본문이 들어있는 tag, 속성 값 등등
모든 언론사의 웹 페이지 규칙을 알고 있다면 url에 따라 어떤 언론사인지 확인하고 본문이 담긴 tag를 찾아 크롤링이 가능할 것입니다.
하지만, 이는 너무 많은 시간이 들기 때문에 효율성이 떨어집니다.
그래서 생각한 여러 방법을 공유하고자 합니다.
방법 1. 네이버 뉴스 검색 시 제목 밑에 보이는 일부 기사 발췌
방법 1은 해당 기사의 url(언론사 웹 페이지)에 들어가지 않고 네이버 뉴스 페이지에서 보이는 일부 기사를 발췌하는 방법입니다.
아래 그림의 빨간색 박스에 해당하는 부분을 크롤링하는 것입니다.

하지만, 여기도 문제가 발생합니다. 본문 전체를 가져오지 못한다는 것입니다.
(HTML 코드 상에서 보면 전체 본문이 아닌 일부 본문만 보여지는 것을 알 수 있습니다)

물론 이 방식으로 진행해도 상관 없다면 위에서 보이는 뉴스 기사별
- class속성값이 "sp_nws"로 시작하는(정규 표현식 사용해야 함) div 태그를 찾고
- 해당 태그 하위의 class 속성값이 "dsc_wrap"인 div 태그를 찾고
- 해당 태그 하위의 a 태그를 찾아 text를 추출하여 크롤링을 진행하면 됩니다(매우 편리합니다)
하지만, 본문 전체를 가져오지 못하기 때문에 큰 의미가 없을 것이라 판단하여 다른 방법을 고민해보았습니다.
방법 2. 일부 언론사 선택 후 기사 본문 크롤링
방법 2는
- 주로 보는 일부 언론사를 몇 개 선택 & 검색한 후
- 해당 언론사 title, url만 크롤링합니다.
- 언론사별로 웹 페이지에서 본문이 위치한 tag를 확인하고
- 해당 url(언론사 웹 페이지)에 들어가서 본문을 크롤링하는 방법입니다.
그래서 추가로 알아봐야 할 것은 다음과 같습니다.
STEP 1. 검색할 언론사 선택
STEP 2. 일부 언론사만 검색하는 기능
STEP 3. 선택한 언론사별 본문 tag 위치
결론적으로 저는 STEP 2에서 많이 애를 먹었습니다.
그 이유는 네이버 뉴스 페이지에서 언론사 선택 시 조건절이 URL에 붙는 방식이 아니기 때문에
웹페이지 제어(동적 크롤링)로 언론사를 선택해야 하기 때문입니다.(네이버 뉴스 페이지 구성 변경 전 내용)
현재 네이버 뉴스 페이지 구성을 확인해본 결과 바뀐 점은 아래와 같습니다
- 여러 언론사를 선택할 수 있었으나, 현재는 언론사 1개만 선택 가능함
- 언론사 선택 시 URL에 조건절이 붙지 않았으나, 현재는 언론사에 해당하는 코드가 URL에 붙음
따라서, 검색할 키워드와 원하는 언론사 코드를 URL에 넣어서 검색한 후
STEP 3를 진행하여 각 뉴스별 언론사 홈페이지 접속 후 본문을 크롤링하면 됩니다.
예를 들어, "코로나"를 키워드로 검색하고, "국민일보"를 언론사로 선택하면 아래와 같은 URL 뒤에 조건이 붙습니다.
https://search.naver.com/search.naver?where=news&query=코로나&sm=tab_opt&sort=0&photo=0&field=0&pd=0&ds=&de=&docid=&related=0&mynews=1&office_type=1&office_section_code=1&news_office_checked=1005&nso=&is_sug_officeid=0
코로나 : 네이버 뉴스검색
'코로나'의 네이버 뉴스검색 결과입니다.
search.naver.com
- 코로나 검색 시 : query=코로나
- 국민일보 선택 시 : news office checked=1005 (1005가 국민일보의 코드로 보입니다)
따라서, 언론사 코드만 알면 해당 언론사를 선택하여 크롤링을 진행할 수 있습니다.
네이버 뉴스 페이지의 HTML 코드를 살펴본 결과 언론사 코드는 다음과 같이 확인할 수 있었습니다.

각 언론사 별로 data-code에 해당하는 것이 언론사 코드인 것 같습니다.
- 국민일보 : 1005
- 경향신문 : 1032
- 등등..
하지만, 본 포스팅에서는 selenium을 이용한 동적 크롤링을 사용하여 언론사를 선택하여 검색된 뉴스 기사를 크롤링하는 내용에 대해 진행해보려 합니다.
가장 먼저! 환경 설정
이에 앞서 먼저 웹페이지 제어를 위한 응용프로그램이 필요하기에 이를 설명드리겠습니다(Chrome 기준)
1. 자신의 Chrome 버전을 확인합니다
- Chrome 창에서 창 상단바 가장 우측의 점 세개 클릭 -> "설정" 클릭 -> 좌측에 "Chrome 정보" 클릭
- 그리고 Chrome 버전을 확인합니다

2. 1에서 확인한 Chrome 버전과 맞는 chromedriver.exe를 설치합니다.
- chromedriver.chromium.org/downloads 접속
- 자신의 Chrome 버전에 맞는 링크를 클릭하고
- chromedriver를 다운 받습니다 (mac, windows 중에 선택)

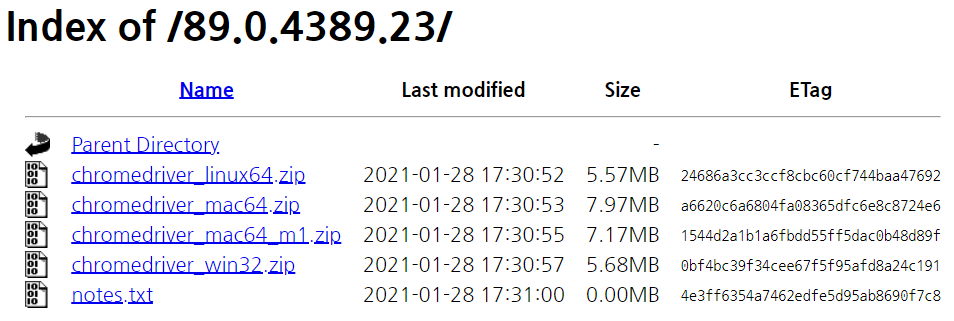
- 다운받은 zip 파일 안에 chromedriver.exe 라는 응용프로그램이 존재하는데
- 압축을 풀고 이를 C드라이브 안에 chromedriver 라는 폴더를 만들고 해당 폴더 안으로 옮겨줍니다 (폴더 경로 : C:/chromedriver/ )
- 아래 제가 구성한 코드에 chromedriver.exe 응용프로그램 파일 경로를 위와 같이 설정하였기에 이렇게 설명드리는겁니다. 다른 경로로 하고 싶으시면 아래 코드의 경로를 바꿔주면 됩니다 ㅎㅎ

이제 이렇게 하면 Chrome을 자동제어할 수 있는 환경이 마련됩니다!
STEP 1. 검색할 언론사 선택
저는 6개의 언론사를 선택했습니다.
(너무 언론사가 많아지면 크롤링 시 본문 tag를 일일이 하드 코딩해주기 힘들기 때문입니다.)
- "연합뉴스", "KBS", "매일경제", "MBC", "SBS", "JTBC"입니다.
위에서 말씀드렸듯이 현재 네이버 뉴스 페이지에서 하나의 언론사만 선택 가능하므로 실제로는 "KBS"로 검색하겠습니다.
STEP 2. 일부 언론사만 검색하는 기능
앞에서 말씀드린 것처럼 네이버 뉴스 페이지에서 언론사를 선택할 때 네이버 뉴스 URL에 조건절이 붙는 방식이 아닙니다.
selenium 패키지로 웹 브라우저를 제어하는 동적 크롤링을 사용하여 언론사를 선택하여 뉴스 기사를 filter하겠습니다.
- url에 키워드를 넣어 검색
- "옵션" bar 활성화
- "언론사 분류순" bar 열기
- "언론사 종류" 선택
- 원하는 언론사 선택

HTML 코드 상에서 각 filter 및 bar의 위치를 확인하면 다음과 같습니다.
① 검색 URL
https://search.naver.com/search.naver?where=news&sm=tab_jum&query=키워드
② "옵션" bar
- 설명 : class 속성 값 = "btn_option _search_option_open_btn"인 a 태그
- xpath
- //a[@class="btn_option _search_option_open_btn"]
- 선택 후 클릭
③ "언론사 분류순" bar
③-1. 전체 박스 선택
- 범위 설정을 위해 해당 내용들을 포함하는 전체 박스 선택
- 설명
- role 속성 값 = "listbox"이고, class 속성 값 = "api_group_option_sort _search_option_detail_wrap"인 div 태그
- 하위 class 속성 값 = "bx press"인 li 태그
- xpath
- //div[@role="listbox" and @class="api_group_option_sort _search_option_detail_wrap"]//li[@class="bx press"]

③-2. "언론사 분류순" bar 클릭
- 설명
- ③-1 태그에서 role 속성값="tablist" 이고, class 속성값="option"인 div 태그
- 하위의 a 태그 중 두 번 째 태그
- xpath
- .//div[@role="tablist" and @class="option"]/a
- 2 번째 a 태그 클릭

④ "언론사 종류" 선택
④-1. 전체 박스 선택
- 설명
- ③-1 태그에서 class 속성값="group_select _list_root"인 div 태그들
- 그 중 첫 번째 태그
- xpath
- .//div[@class="group_select _list_root"]
- 중 첫 번째 태그

④-2. 언론사 종류 선택
- 설명
- ④-1 태그에서 role 속성값="tablist"이고, class 속성값="lst_item_ul"인 ul 태그
- 하위의 li 태그
- 하위의 a 태그들
- xpath
- .//ul[@role="tablist" and @class="lst_item _ul"]/li/a

⑤ 언론사 선택
- ④-2에서 언론사 종류를 선택해가며, 우측에 나타나는 언론사 리스트 중 원하는 언론사(KBS)가 있는지 확인
- 있으면, 클릭 후 종료
- 없으면, 다음 언론사 종류로 이동
⑤-1. 전체 박스 선택
- 설명
- ③-1 태그에서 class 속성값="group_select _list_root"인 div 태그들
- 그 중 두 번째 태그
- xpath
- .//div[@class="group_select _list_root"]
- 중 첫 번째 태그

⑤-2. 언론사 선택
검색하고자 하는 언론사(KBS)와 현재 태그 언론사와 같은 경우 클릭하고 ⑤을 종료합니다
- 설명
- ⑤-1 태그에서 role 속성값="tablist"이고, class 속성값="lst_item_ul"인 ul 태그
- 하위의 li 태그
- 하위의 a 태그들
- xpath
- .//ul[@role="tablist" and @class="lst_item _ul"]/li/a

- 설명 : ③-3 태그 → class 속성값="scroll_area _panel_filter_"인 div 태그 → class 속성값="select_item"인 div 태그
- x
STEP 3. 선택한 언론사별 본문 tag 위치
각 언론사를 확인한 결과 url 패턴과 본문 tag 위치는 다음과 같습니다.
▶ Chrome으로 언론사의 아무 뉴스나 들어가셔서
본문에 커서를 위치 > 우클릭 > 검사(N)를 누르시면 본문이 위치한 태그를 확인하실 수 있습니다.
| 언론사 | url | 본문을 담고 있는 태그 위치 |
| 연합뉴스 | www.yna.co.kr/ | //div[@class=“story-news article”] 또는 //div[@class=“article-txt”] |
| 연합뉴스(앱용) | http://app.yonhapnews.co.kr/ | |
| 매일경제 | https://www.mk.co.kr/ | //div[@class=“art_txt”] |
| 매일경제(미라클) | https://mirakle.mk.co.kr/ | //div[@class=“view_txt”] |
| MBC | https://imnews.imbc.com/ | //div[@itemprop=“articleBody”] |
| SBS | https://news.sbs.co.kr/ | //div[@id=“articleBody”] |
| KBS | http://news.kbs.co.kr/ | //div[@id=“cont_newstext”] |
| JTBC | http://news.jtbc.joins.com/ | //div[@class=“article_content”] |
뉴스 title, URL 추출 후 URL의 조건에 따라 알맞은 언론사의 본문 tag를 찾는 코드를 구현하면 됩니다.
방법 2의 실행결과
실행결과는 다음과 같습니다.
브라우저를 selenium이 제어하여 뉴스를 크롤링하고 완료된 후 브라우저를 종료합니다.
그 후 결과물을 엑셀 파일로 저장하고 해당 폴더를 열어줍니다.
(이 부분은 경로가 들어가 있어 영상에서 제외하였습니다.)
코드 - 방법2
전체 코드는 다음과 같습니다.
import sys, os
import requests
import selenium
from selenium import webdriver
import requests
from pandas import DataFrame
from bs4 import BeautifulSoup
import re
from datetime import datetime
import pickle, progressbar, json, glob, time
from tqdm import tqdm
###### 날짜 저장 ##########
date = str(datetime.now())
date = date[:date.rfind(':')].replace(' ', '_')
date = date.replace(':','시') + '분'
sleep_sec = 0.5
####### 언론사별 본문 위치 태그 파싱 함수 ###########
print('본문 크롤링에 필요한 함수를 로딩하고 있습니다...\n' + '-' * 100)
def crawling_main_text(url):
req = requests.get(url)
req.encoding = None
soup = BeautifulSoup(req.text, 'html.parser')
# 연합뉴스
if ('://yna' in url) | ('app.yonhapnews' in url):
main_article = soup.find('div', {'class':'story-news article'})
if main_article == None:
main_article = soup.find('div', {'class' : 'article-txt'})
text = main_article.text
# MBC
elif '//imnews.imbc' in url:
text = soup.find('div', {'itemprop' : 'articleBody'}).text
# 매일경제(미라클), req.encoding = None 설정 필요
elif 'mirakle.mk' in url:
text = soup.find('div', {'class' : 'view_txt'}).text
# 매일경제, req.encoding = None 설정 필요
elif 'mk.co' in url:
text = soup.find('div', {'class' : 'art_txt'}).text
# SBS
elif 'news.sbs' in url:
text = soup.find('div', {'itemprop' : 'articleBody'}).text
# KBS
elif 'news.kbs' in url:
text = soup.find('div', {'id' : 'cont_newstext'}).text
# JTBC
elif 'news.jtbc' in url:
text = soup.find('div', {'class' : 'article_content'}).text
# 그 외
else:
text = None
return text.replace('\n','').replace('\r','').replace('<br>','').replace('\t','')
press_nm = 'KBS'
print('검색할 언론사 : {}'.format(press_nm))
############### 브라우저를 켜고 검색 키워드 입력 ####################
query = input('검색할 키워드 : ')
news_num = int(input('수집 뉴스의 수(숫자만 입력) : '))
print('\n' + '=' * 100 + '\n')
print('브라우저를 실행시킵니다(자동 제어)\n')
chrome_path = 'C:/chromedriver/chromedriver.exe'
browser = webdriver.Chrome(chrome_path)
news_url = 'https://search.naver.com/search.naver?where=news&query={}'.format(query)
browser.get(news_url)
time.sleep(sleep_sec)
######### 언론사 선택 및 confirm #####################
print('설정한 언론사를 선택합니다.\n')
search_opn_btn = browser.find_element_by_xpath('//a[@class="btn_option _search_option_open_btn"]')
search_opn_btn.click()
time.sleep(sleep_sec)
bx_press = browser.find_element_by_xpath('//div[@role="listbox" and @class="api_group_option_sort _search_option_detail_wrap"]//li[@class="bx press"]')
# 기준 두번 째(언론사 분류순) 클릭하고 오픈하기
press_tablist = bx_press.find_elements_by_xpath('.//div[@role="tablist" and @class="option"]/a')
press_tablist[1].click()
time.sleep(sleep_sec)
# 첫 번째 것(언론사 분류선택)
bx_group = bx_press.find_elements_by_xpath('.//div[@class="api_select_option type_group _category_select_layer"]/div[@class="select_wrap _root"]')[0]
press_kind_bx = bx_group.find_elements_by_xpath('.//div[@class="group_select _list_root"]')[0]
press_kind_btn_list = press_kind_bx.find_elements_by_xpath('.//ul[@role="tablist" and @class="lst_item _ul"]/li/a')
for press_kind_btn in press_kind_btn_list:
# 언론사 종류를 순차적으로 클릭(좌측)
press_kind_btn.click()
time.sleep(sleep_sec)
# 언론사선택(우측)
press_slct_bx = bx_group.find_elements_by_xpath('.//div[@class="group_select _list_root"]')[1]
# 언론사 선택할 수 있는 클릭 버튼
press_slct_btn_list = press_slct_bx.find_elements_by_xpath('.//ul[@role="tablist" and @class="lst_item _ul"]/li/a')
# 언론사 이름들 추출
press_slct_btn_list_nm = [psl.text for psl in press_slct_btn_list]
# 언론사 이름 : 언론사 클릭 버튼 인 딕셔너리 생성
press_slct_btn_dict = dict(zip(press_slct_btn_list_nm, press_slct_btn_list))
# 원하는 언론사가 해당 이름 안에 있는 경우
# 1) 클릭하고
# 2) 더이상 언론사분류선택 탐색 중지
if press_nm in press_slct_btn_dict.keys():
print('<{}> 카테고리에서 <{}>를 찾았으므로 탐색을 종료합니다'.format(press_kind_btn.text, press_nm))
press_slct_btn_dict[press_nm].click()
time.sleep(sleep_sec)
break
################ 뉴스 크롤링 ########################
print('\n크롤링을 시작합니다.')
# ####동적 제어로 페이지 넘어가며 크롤링
news_dict = {}
idx = 1
cur_page = 1
pbar = tqdm(total=news_num ,leave = True)
while idx < news_num:
table = browser.find_element_by_xpath('//ul[@class="list_news"]')
li_list = table.find_elements_by_xpath('./li[contains(@id, "sp_nws")]')
area_list = [li.find_element_by_xpath('.//div[@class="news_area"]') for li in li_list]
a_list = [area.find_element_by_xpath('.//a[@class="news_tit"]') for area in area_list]
for n in a_list[:min(len(a_list), news_num-idx+1)]:
n_url = n.get_attribute('href')
news_dict[idx] = {'title' : n.get_attribute('title'),
'url' : n_url,
'text' : crawling_main_text(n_url)}
idx += 1
pbar.update(1)
if idx < news_num:
cur_page +=1
pages = browser.find_element_by_xpath('//div[@class="sc_page_inner"]')
next_page_url = [p for p in pages.find_elements_by_xpath('.//a') if p.text == str(cur_page)][0].get_attribute('href')
browser.get(next_page_url)
time.sleep(sleep_sec)
else:
pbar.close()
print('\n브라우저를 종료합니다.\n' + '=' * 100)
time.sleep(0.7)
browser.close()
break
#### 데이터 전처리하기 ######################################################
print('데이터프레임 변환\n')
news_df = DataFrame(news_dict).T
folder_path = os.getcwd()
xlsx_file_name = '네이버뉴스_본문_{}개_{}_{}.xlsx'.format(news_num, query, date)
news_df.to_excel(xlsx_file_name)
print('엑셀 저장 완료 | 경로 : {}\\{}\n'.format(folder_path, xlsx_file_name))
os.startfile(folder_path)
print('=' * 100 + '\n결과물의 일부')
news_df마치며
완벽하게 모든 언론사의 본문을 가져오지 못했지만
주로 보는 언론사만으로도 충분한 정보를 얻을 수 있을 것 같습니다.
뉴스를 읽다 보면 언론사가 다르고, 안의 문장이 다르지만 같은 사건이나 이슈를 다루는 경우가 많습니다.
이런 경우는 같은 내용의 기사이기에 중복을 제거해주는 것이 좋겠지요.
매우 어려운 주제이지만 고민해서 다음 포스팅을 진행할까 합니다.
긴 글 읽어주셔서 감사합니다~
피드백은 언제나 저에게 도움이 됩니다 :)
'코딩' 카테고리의 다른 글
| 수치 미분을 해보자 (0) | 2023.09.23 |
|---|---|
| [아래한글 자동화] 보안승인모듈 등록 (3) | 2020.09.02 |
| [2탄] 쉽게 따라하는 네이버 뉴스 크롤링(python) - title, URL 가져오기 (23) | 2020.08.30 |
| [1탄] 쉽게 따라하는 네이버 뉴스 크롤링(python) - 계획 짜기 (2) | 2020.08.30 |



